Notes on building four engines — three for inference, one for simulation — where none were expected.
-
July 2026
Two Backends, One Posterior
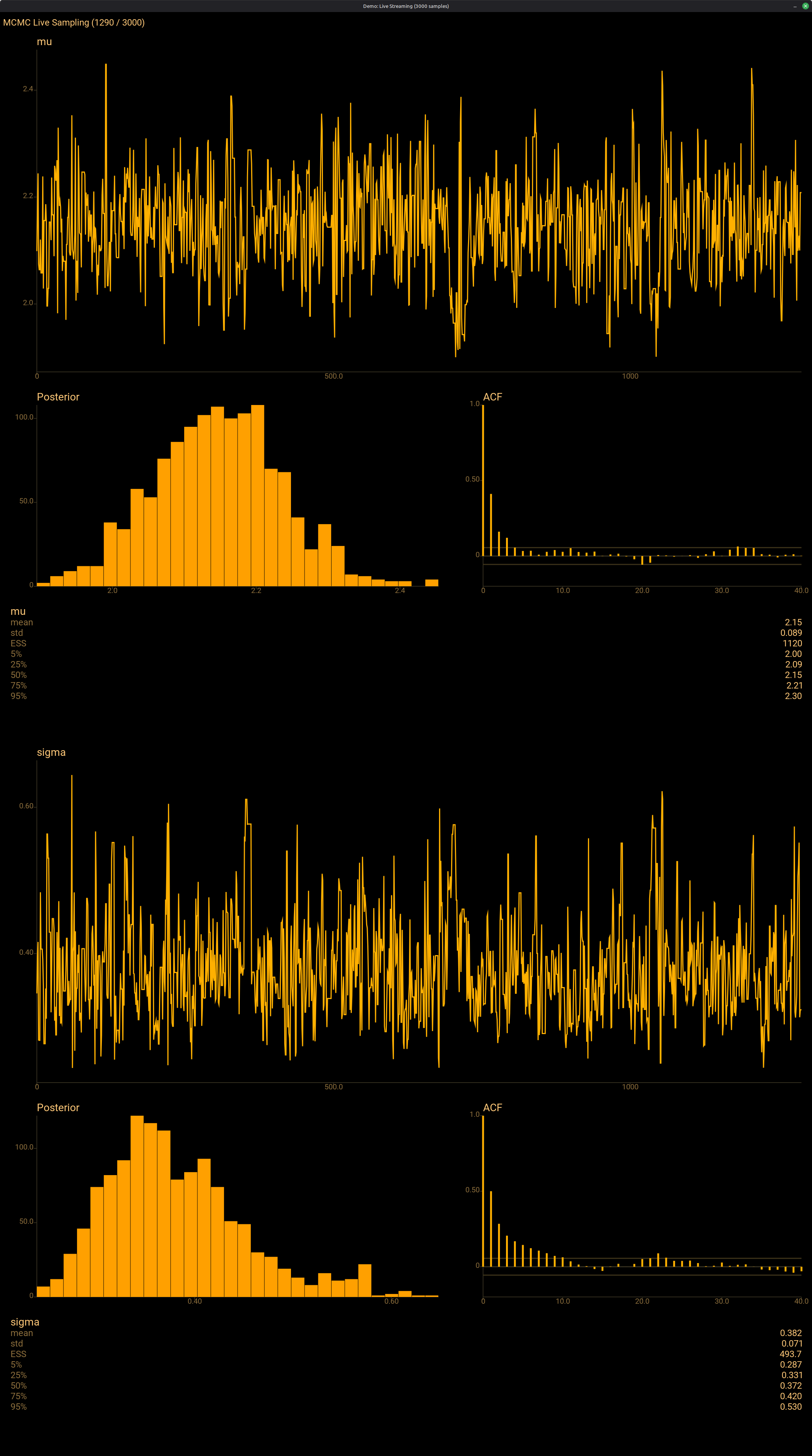
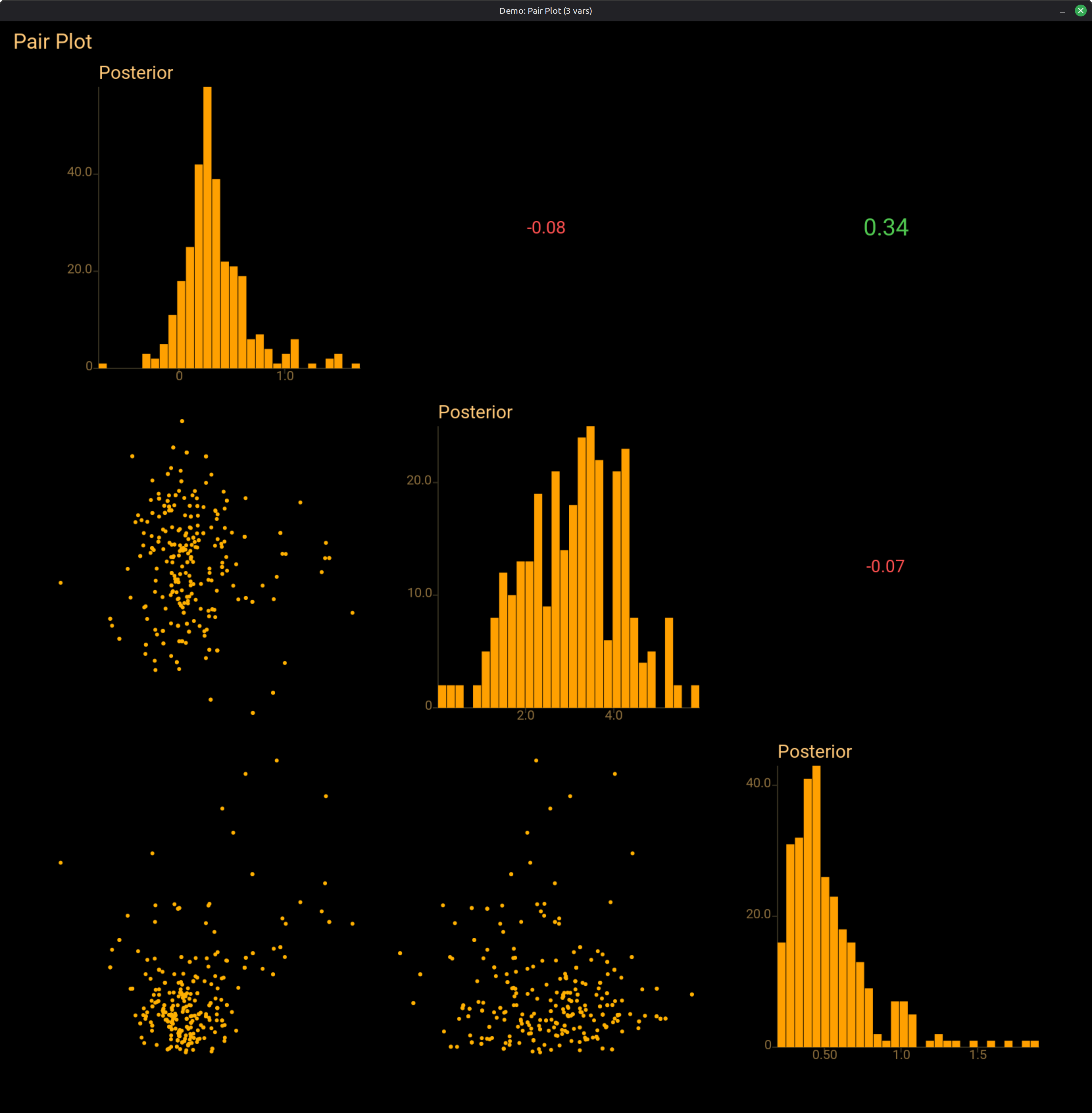
A GPU chain shader for Bayesian inference on FreeBSD passed correctness tests that no reasonable test suite should have written. The passing tolerance was wrong, the failing tolerance was wronger, and the third revision was wrong for a different reason. What emerged is a verification standard for probabilistic backends: statistical parity, robust to heavy tails, oblivious to floating-point associativity. Cross-Kepler byte-identity at two thousand samples came for free.
-
July 2026
Two GPUs, Two FreeBSD Boxes, One Erlang Cluster
A dual-GPU Bayesian inference demo built from two 2013 Mac Pros, a $5 ethernet cable, and no service mesh. Erlang distribution as GPU dispatch fabric — two lines of Elixir replace what would otherwise be a Protobuf schema, a generated stub, and a service-mesh sidecar. The compute is a single SPIR-V binary loaded unmodified on two Kepler generations; a fused leapfrog chain shader amortises ~384 fence waits per iteration down to ~4, an 86.7× speedup with no change in numerical output. 400 NUTS samples in 1.3 seconds across two operating systems and a decade of hardware — what falls out when the transport, the compute, and the abstraction were already there.
-
June 2026
Three Minutes, Then a Crash
A retrospective, two weeks after the C++ → vulkano migration shipped. The crash, the spike that produced byte-identical output on the first try, the descriptor pool that ate the production GPU, the autograd that fell out for free — in compressed form. The payoff is the property nobody had asked for: under BinaryBackend with :rand, mac-247 and mac-248 produced bit-identical step sizes, divergence counts, and posterior means across all 33 posteriordb regression models. Pre-fix 28/1/4, post-fix 31/2/0, identical on both hosts. The backend that worked best was the one that knew the least, and the properties that fell out are the ones most likely to survive the next refactor.
-
May 2026
From 0.02× to 34×: How One Op Got Native
The op-only bench was correct: concatenate on the new VulkanoBackend ran at 0.02× BinaryBackend — 500× slower at 1M elements. It was also irrelevant. The consumer-aware bench (five columns, not three) revealed where the cost actually lived: a gratuitous upload-back at the end of every host-fallback callback, paid by every caller, measured by no one. Tier 1 (a five-line patch per op) removed the tax. Tier 2 (eighty lines of Rust and an all_vulkano? predicate) replaced the host fallback with vkCmdCopyBuffer, no shader required. Same op, now sub-1.0 D/B at every size on both a 3060 Ti and a 2012 GT 650M — with the cross-host inversion at small N surfacing again: FreeBSD’s leaner driver path edges Linux’s when dispatch overhead dominates.
-
May 2026
Three Shapes of Vulkano Speedup
309 benchmarks across two machines — a 2021 RTX 3060 Ti on Linux and a 2013 GT 750M on FreeBSD — reveal three distinct speedup-vs-size shapes for the new VulkanoBackend. Compute-bound ops (matmul, big elementwise) scale to 10,000× on the modern card. Dispatch-bound reductions hump up to 7× around 256k elements, then fall back toward parity. Host-fallback ops always lose — concatenate at 0.02× is the worst. The twist: at small sizes, the thirteen-year-old GT 750M on FreeBSD beats the 3060 Ti by 30-50% on dispatch-bound work. A simpler driver path with no display server competing for the queue eats less per-dispatch tax than Linux. Three curves, two machines, one architectural lesson: use the right backend at the right size.
-
May 2026
The Backend That Didn’t Need to Know
A Vulkan compute backend in C++ crashed three minutes after every restart — a use-after-free across the FFI boundary that no documentation could prevent. The replacement was a pure-Rust crate using vulkano. Same SPV file, byte-identical output, built on FreeBSD in 3:18. Then came the descriptor-pool puzzle (vulkano creates a fresh pool per unique PipelineLayout identity, and our per-call layouts never recycled), the cross-host race (a 2013 GT 650M faster than an RTX 3060 Ti on small dispatch), and the autograd reveal: Nx.Defn.grad transforms graphs, not backends. Twenty-six lines of code where Stage 8 had budgeted a session. The backend that worked best was the one that knew the least.
-
May 2026
Zed and Its Satellites
A state-of-the-project post for May 2026. The pièce de résistance is a single DSL verb — host — that turns hand-rolled :rpc.call sequences into declarative multi-host deploys, backed by a TLA+-verified two-phase commit protocol. Twelve lines of DSL produce a 100-millisecond two-host coordinated deploy across two Erlang-distributed FreeBSD Mac Pros. Plus the satellites: probnik_qr (planned), nx_vulkan (Phase 2 shipped), exmc (NUTS on GPU), spirit (vendored), and the writing surface this post sits on. Six repositories, one BEAM cluster, three operating systems, two GPUs from 2013, and a deliberate refusal to call any of it a platform.
-
May 2026
TLA+ Caught the Bug We Shipped
Two FreeBSD Mac Pros, one Erlang cluster, a chaos test that surfaced exactly the kind of bug a coordinated deployment tool must never ship: a dataset survived on mac-248 when mac-247 failed mid-converge. The fix was a 200-line TLA+ specification of the protocol — and the model checker found a second bug five rounds of manual chaos testing had missed. The spec runs in 0.8 seconds. The bug had cost half a day. Zed’s coordinated converge is now a TLA+-verified 2-phase protocol with three invariants. Write the spec first.
-
May 2026
Vulkan on FreeBSD: the Proof
A follow-up measurement to The GPU That Doesn’t Need CUDA. Two 2013 Mac Pros with GT 750M and GT 650M GPUs running FreeBSD beat a 2021 Linux workstation with an RTX 3060 Ti at Bayesian inference. Per-fence instrumentation explains why: FreeBSD’s NVIDIA driver completes vkWaitForFences in 406 µs; Linux’s takes 1,130 µs on the same driver family. Fused leapfrog chain shaders amortize the dispatch overhead 86× over per-op dispatch. One second per 2000 NUTS iterations on a decade-old GPU. The walkable path has now been walked, and the measurements are attached.
-
May 2026
A Walkable Path Under the Mountain
Three workstreams just converged. nx_vulkan reached 152/0 on Linux RTX 3060 Ti. The Bastille adapter shipped to zed. The eXMC NUTS sampler runs against a Vulkan backend with no code changes. Together that means a sentence is now true that wasn’t in February: write a probabilistic model in Elixir, ship it to a FreeBSD jail managed by zed, and have it sample on the host’s GPU through Vulkan compute pipelines — no CUDA anywhere in the chain. The mountain of CUDA sophistication is still there. The point was never to climb it. The point was to demonstrate we don’t have to.
-
April 2026
What the Mutex Saved
From `mix new` to a working Nx tensor backend on Vulkan in seven commits. The bootstrap was the easy part. The hard part was the moment 100 BEAM processes simultaneously called `vkQueueSubmit` and the NVIDIA driver responded by losing the device. What the Vulkan spec said, what the Erlang scheduler did, and what one `Mutex<()>` in Rust bought back. Plus the speedup number nobody who runs FreeBSD will quite believe — three thousand times over Nx.BinaryBackend at four million elements, zero leaked megabytes after thirty seconds of churn, and what falls out the other side when both bugs are interesting.
-
April 2026
The GPU That Doesn’t Need CUDA
A Vulkan compute backend for the Spirit spin simulator, built on a 2013 Mac Pro running FreeBSD with a GT 750M, then ported to a Linux box with an RTX 3060 Ti. The 750M proved the FreeBSD path works (1.66x at 1M); the 3060 Ti proved it scales (8.8x at 1M, 13.3x at 4M). Same backend code, same shader, same 540 lines of C++. What it opens up: Nx.Vulkan for Elixir GPU on BSD, GPU-inference jails on FreeBSD, an exit door from the CUDA platform-lock that’s been there the whole time.
-
April 2026
What Zed Is, Now
A reintroduction to Zed after A0 through A5a + A1.rotate landed. Three thousand lines of Elixir, eighty lines of C, one filesystem, no etcd. ZFS user properties as the state store, encrypted secrets with archived rotation, a Bastille adapter that catches the upstream CLI’s lies, and a process-boundary privilege model where zedweb cannot reach root. What it gives you, what’s not yet in the box, and how it’s tested.
-
April 2026
The Lie at Exit Zero
A 540-line Elixir adapter to FreeBSD’s Bastille jail manager. 175 mocked unit tests passed cleanly on a Linux laptop. The first live run on real FreeBSD hardware found seven distinct failures in sequence — none of which any mock could have predicted. What the mock did not know, what the post-condition check finally caught, and why the punchline of an adapter is the line where it stops trusting the tool it adapts.
-
April 2026
What the Pool Remembers
A FreeBSD NAS I will probably never build. The design arc from rebuild fantasy to a 14-person-month MVP, and what the detour taught about secret hygiene on the BEAM: ZFS user properties as metadata backbone, QR-paired admin login, a phone-resident vault that implements its own Shamir, and the seven ways to lose your keys for good.
-
April 2026
Vehtari’s Course in a Different Language
The official BDA3 Python demos, ported to Elixir Livebooks. 22 demos across 8 chapters. 13 Stan files translated. 8 datasets vendored. Every numerical claim verified. Same pedagogy, different runtime virtues.
-
April 2026
Eighty-Seven Idle Schedulers
Load average 1.0 on 88 cores. One scheduler working, eighty-seven watching. Until you run 1,000 replications — then they all work, and the analysis takes 207 milliseconds.
-
April 2026
Two Functions I Didn’t Refactor
Fourteen functions met a pattern-matching rule. Twenty-one call sites met a pipe rule. The two I didn’t refactor and the one I didn’t pipe are the real deliverable — the taxonomy of when NOT to.
-
April 2026
The Clipboard, the Auditor, and the Saboteur
A factory floor has three kinds of inspectors. The first two are familiar. The third is the one that finds the bug. Testing simulation engines, explained for industrial engineers.
-
April 2026
Four Months, Eight Hundred Lines
Two NUTS sampler bugs took four months to find by hand. Every test passed. The chain converged at half the speed it should have. The proper_statem models that catch them are eight hundred lines — The Mechanic and the Transporter — and the postcondition is a histogram, not an invariant.
-
April 2026
The Release That Never Seized
700 adversarial command sequences. Three state machine models. One bug that 114 tests missed: you can release a resource you never held, and the engine says thank you.
-
April 2026
The Invariants Were Always There
Seed 42 is an anecdote. 350 trials across random parameter spaces proved Little’s Law, flow conservation, and determinism. They also found a bug that 77 point tests missed for four months.
-
April 2026
Thirty to One
Elixir sequential is slower than SimPy. Elixir parallel is 9x faster. Rust parallel is 30x. The BEAM’s advantage is not per-event speed — it’s per-replication concurrency. 1,000 reps in 207 milliseconds.
-
April 2026
The Map That Remembers Too Much
At 100,000 entities, Elixir’s persistent Map creates six garbage nodes per event. ETS doesn’t. But the crossover isn’t where you’d expect — it depends on whether you pin your BEAM schedulers to NUMA nodes. A story about garbage.
-
April 2026
Le Simulateur
Building a discrete-event simulation engine on the BEAM. 539,000 events per second. The actor model is the right abstraction for the system, the wrong abstraction for the inner loop. On why GenServers cost 7.8× in the hot path.
-
March 2026
The Five Hundred Iterations You Run Twice
5.8× NUTS warmup speedup by reusing the previous posterior's mass matrix. When the data barely changes, so does the posterior geometry. One keyword argument.
-
March 2026
The 34% You Leave on the Table
How one Erlang flag turned 0.73 jobs/sec into 0.98 on 88 cores doing Bayesian MCMC. On NUMA-aware scheduler binding, the naming of tnnps, and why the BEAM's defaults are wrong for compute-bound work.
-
February 2026
The Amber Trace
On the improbable and slightly reckless decision to build a probabilistic programming framework on a virtual machine designed for telephone switches. A literary technical memoir in twelve chapters.
-
January 2026
34× Slower to 1.9× Faster: The Optimization Journey
Seven optimization phases, each revealing something about mixed-runtime Probabilistic Programming design. From 3.3 ESS/s to 298 ESS/s without changing the algorithm.
-
January 2026
Feature Parity and Speed
16 distributions, 4 inference methods, GPU acceleration, and a head-to-head race against PyMC. The numbers that prove the thesis.
-
December 2025
What If Probabilistic Programming Runtimes Were Different?
The architectural thesis: streaming, fault tolerance, and distribution as consequences of the runtime, not features bolted on. Part 1 of the series.